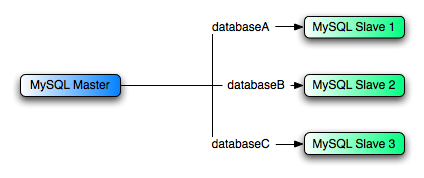
There may be situations where you have a single master and want to replicate different databases to different slaves. For example, you may want to distribute different sales data to different departments to help spread the load during data analysis. A sample of this layout is shown in Figure 16.2, “Using Replication to Replicate Databases to Separate Replication Slaves”.
You can achieve this separation by configuring the master and
slaves as normal, and then limiting the binary log statements that
each slave processes by using the
--replicate-wild-do-table
configuration option on each slave.
Important
You should not use
--replicate-do-db for this
purpose when using statement-based replication, since
statement-based replication causes this option's affects to
vary according to the database that is currently selected. This
applies to mixed-format replication as well, since this allows
some updates to be replicated using the statement-based format.
However, it should be safe to use
--replicate-do-db for this
purpose if you are using row-based replication only, since in
this case the currently selected database has no effect on the
option's operation.
For example, to support the separation as shown in
Figure 16.2, “Using Replication to Replicate Databases to Separate Replication Slaves”, you should
configure each replication slave as follows, before executing
START SLAVE:
Replication slave 1 should use
--replicate-wild-do-table=databaseA.%.Replication slave 2 should use
--replicate-wild-do-table=databaseB.%.Replication slave 3 should use
--replicate-wild-do-table=databaseC.%.
Each slave in this configuration receives the entire binary log
from the master, but executes only those events from the binary
log that apply to the databases and tables included by the
--replicate-wild-do-table option in
effect on that slave.
If you have data that must be synchronized to the slaves before replication starts, you have a number of choices:
Synchronize all the data to each slave, and delete the databases, tables, or both that you do not want to keep.
Use mysqldump to create a separate dump file for each database and load the appropriate dump file on each slave.
-
Use a raw data file dump and include only the specific files and databases that you need for each slave.
Note
This does not work with
InnoDBdatabases unless you useinnodb_file_per_table.
User Comments
Add your own comment.