障害が発生した場合にマスタとスレーブ間でのフェイルオーバに対応する正式なソリューションは現在の段階ではありません。現在利用可能な機能内では、マスタとスレーブ (または複数のスレーブ) をセットアップし、状況を把握するためにマスタを監視するスクリプトを作成することが挙げられます。そのときには、アプリケーションとスレーブに障害を認識した場合にマスタを変更するよう指示します。
CHANGE MASTER TO
ステートメントを使用して、いつでもスレーブにマスタを変えるように指示することが重要です。スレーブはマスタのデータベースがスレーブとの互換性を保持しているかどうかを確認することができないため、新しいマスタが指定するログと場所からイベントを実行し始めます。フェイルオーバの状況で、グループ内すべてのサーバが同一のバイナリ
ログからの同一のイベントを実行しています。そのため、イベント元の変更がデータベース
ストラクチャまたは整合性に影響することのないように慎重に扱う必要があります。
スレーブを --log-bin はあるけれども
--log-slave-updates
はないという組み合わせで実行します。この方法では、スレーブで
RESET MASTER と CHANGE MASTER
TO を実行し、別のスレーブで STOP
SLAVE
を実行すると同時に、スレーブがマスタになる準備ができます。図 5.9. 「レプリケーションを活用した冗長性、初期ストラクチャ」
のストラクチャで例示を参照してください。
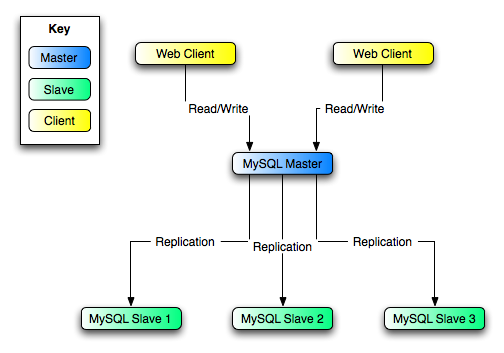
この図では、MySQL Master にはマスタ
データベースがあり、MySQL Slave
のコンピュータはレプリケーション
スレーブ、そして Web Client
マシンは読み書き込みをするデータベースという関係になります。通常スレーブに接続していて読み込みだけを行うウェブ
クライアントは、障害イベントで新しいサーバへは切り替わらないため、図には含まれていません。読み書き込みのスケールアウト
ソリューション
ストラクチャに関しては、項5.3.3. 「スケールアウトのレプリケーション」
を参照してください。
MySQL Slave のそれぞれ (Slave
1、Slave 2、Slave
3) は、 --log-slave-updates
を伴わずに、--log-bin
だけで実行しているスレーブです。--log-slave-updates
の指定がなければマスタからスレーブが受信したアップデートがバイナリ
ログに記録されないため、それぞれのスレーブのバイナリ
ログは最初から空です。 何らかの原因により
MySQL Master
が利用不可になる場合、複数あるスレーブの中から新しいマスタを選ぶことができます。たとえば、Slave
1 を選択する場合、すべての Web
Clients を Slave 1
にリダイレクトして、そこのバイナリ ログ
にアップデートを記録します。つまり、Slave
2 と Slave 3 は Slave
1 から複製することになります。
--log-slave-updates
なしで実行するという理由には、複数のスレーブの中から一つが新たなマスタに切り替わるときに、アップデートを
2
度受信しないようにするためです。たとえば、Slave
1 は --log-slave-updates
するようになると、Master
から受信するアップデートを自分のバイナリ
ログに書き込みます。Slave 2 が
Master から Slave 1
に切り替わった場合は、Master
からアップデートをすでに受信しているにも関わらず、Slave
1
から再度、アップデートを受信するという結果になります。
すべてのスレーブがリレー
ログ内のクエリを処理したかどうかを確認してください。それぞれのスレーブでは、STOP
SLAVE IO_THREAD を発行して、Has read all
relay log を確認できまるまで、SHOW
PROCESSLIST の出力をチェックします。
すべてのスレーブでこれが確認できたら、これらを新たな設定として構成できます。マスタに昇格した
Slave 1 のスレーブでは、STOP
SLAVE と RESET MASTER
を発行します。
別のスレーブ Slave 2 と Slave
3 では、STOP SLAVE
とCHANGE MASTER TO
MASTER_HOST='Slave1' を使います。
('Slave 1'
が、Slave1
の実際のホスト名を表示する場合).CHANGE
MASTER には、Slave 2 または
Slave 3 から Slave 1
へのどのようにするかに関するすべての情報を付加します。(user、password、port
など) CHANGE MASTER では、Slave
1 のバイナリ
ログ名や読み込み先のバイナリ
ログ位置を指定する必要はありません。CHANGE
MASTER
のデフォルトでは、一番初めのバイナリ
ログ、そして位置は 4
です。そして最後に、Slave 2 と
Slave 3 で START SLAVE
を使用します。
新たなレプリケーションを整えた後に、Web
Client が Slave 1
へクエリを送信するよう指示します。この時点から、Web
Client が Slave 1
へ送信したすべてのアップデート クエリが
Slave 1 のバイナリ
ログに書き込まれ、すでに Master
は機能していないため、Slave 1
へ送信したすべてのアップデート
クエリが含まれることになります。
サーバ ストラクチャの結果は 図 5.10. 「レプリケーションを活用した冗長性、マスタ障害後」 に示す通りです。
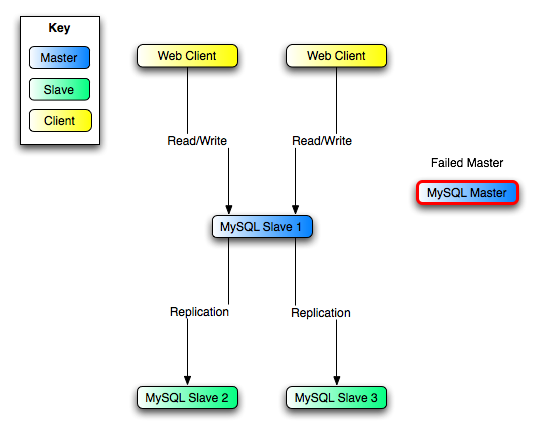
Master
マスタの再稼動するときは、Slave 2
と Slave 3
に発行した通りに、同様の CHANGE
MASTER
を発行してください。これにより、Master
はスレーブの S1
になり、ダウン後に実行された Web
Client の書き込みをすべてピック
アップします。
たとえば、マスタが最もパワフルなマシンであるなど物理的な理由で、Master
をマスタへ戻すには、Slave 1
を利用不可の状態、Master
が新たなマスタになる、というようにそれぞれの立場を逆にしてこの手順を繰り返します。
この手順では、Slave 1、Slave
2 そして Slave 3 を
Master
のスレーブにする前に、Master に
RESET MASTER
を実行することを忘れないでください。これをしないと、Master
が動かなくなる前の古い Web Client
書き込みをピック アップすることになります。
複数スレーブとマスタは同期していません。スレーブのいくつかは他のスレーブよりも前に出ていることがあります。つまり、前述の例で示したコンセプトが機能しない可能性があるということです。しかし、実情では、複数スレーブのリレー ログがマスタからそれほど遅れをとらないので、この方法が適用できるとの考えに基づいています。そのため、この方法が確証できるものではないことに留意してください。
動的な DNS
エントリをマスタに持たせると、マスタの位置に応じてアプリケーションを調節することをお勧めします。bind
で、 DNS を動的に更新するnsupdate
を使います。